Pharmaceutical company improves OEE by 10% in 6 months by achieving maintenance excellence

Read the story


March 12th, 2015
In this article we are going to go over what Text Mining is and how Otofacto successfully researched Digital Technologies for the Manufacturing Industry.
Text mining, sometimes referred to as information data mining, is the act of converting unstructured text into a structured format in order to uncover relevant patterns and fresh insights. Companies can explore and identify hidden links within their unstructured data by using advanced analytical approaches.
Text is one of the most commonly used data types in databases. Depending on the database, this information can be structured as follows:
Text mining is an automated process that uses Natural Language Processing (NLP) to extract important insights from unstructured text. Text mining automates text classification by sentiment, topic, and intent by transforming data into information that machines can understand.
Let’s dive deeper into unstructured data.
Major portions of the information companies store are in the form of unstructured data from texts in natural language. Correspondence, contracts, reports, and studies with business relevance are some of the text types that companies archive. Furthermore, countless external web sites and services are available over the Internet, potentially containing valuable industry-relevant information in news reports, product reviews, and press releases.
Text mining offers a number of established methods for analyzing unstructured texts with the aim of extracting knowledge efficiently and effectively from a corpus. These methods involve using statistical methods or artificial intelligence (AI) to enhance texts with a semantic structure, that enables the corpus to be searched, summarized, and described. As a result, the knowledge contained in the texts is accessible quickly and easily, and can be absorbed more broadly.
In this article, we demonstrate how productivity in R&D companies can be increased through the use of text mining analysis on corpora of research papers. In the example of use from our own research, the structuring and synthesis of literature is automated to support a literature review about sensor data applications in industrial manufacturing.
The results graphically exhibit the potential of the analysis model applied.
Research and development are fundamental building blocks for a highly productive industrial sector and key requirements for future growth. Measured against their per-capita productivity, R&D companies perform significantly better in comparison to non-R&D organizations – and that gap is widening. What’s more, they fare better in international competition thanks to their innovative products and business models.
Improving knowledge workers’ productivity in R&D companies presents a central challenge to managers. With their ideas and expertise, knowledge workers are the main drivers of innovation and profitable results from research and development.
To build on and expand their valuable knowledge, they must, above all, read extensively in order to make sense of a broad range of industry-specific research literature. Literature reviews serve the purpose of building on already existent knowledge. Therefore, they are an indispensable part of any research project. By identifying and synthesizing relevant scientific sources, literature reviews provide a structured view of the research field. However, this is becoming an increasingly complex and time-consuming task. As thousands of new research papers are published every day and the rate of publication is continuing to grow exponentially, structuring and synthesizing relevant research papers becomes a perpetual task – oftentimes one that seems impossible to perform due to the huge volume of literature available.
To support its own research activities and offer R&D companies a tool to overcome this issue, Otofacto developed a text mining analysis model that is capable of automatically structuring and synthesizing a collection of research papers. It should be mentioned, however, that the model developed can be applied not only to research scenarios, but also generally to any collection of texts and documents and a range of use cases.
The result of the analysis model is a structured list of titles of research papers or texts, which are subdivided into thematically linked groups in the form of a dendrogram. Groups with similar topics are located close to each other – and within the groups, too, titles of similar works are in close proximity. The groups found in this way are given meaningful key words as titles, which provide information about the topics within the group in each case.
Because the research papers used in literature searches usually exist as PDF files, the first step is to extract the texts from the documents by means of optical character recognition and convert them into a consistent format. The texts extracted in this way then enter the next stage of preparation, where unimportant words are filtered out using a stopword list.
By looking at word frequencies across the entire corpus, problem-specific words can be identified to be added to the stopword list for each use case. With stemming or lemmatization, the words that remain after filtering are reduced to their stem or lemma. With the texts prepared in this way, neuronal networks are then trained to be able to predict the next word in a given word context.
After training, a vector representation (in other words: a numerical representation) is produced for every text from the hidden neuronal layer. This representation enables similarity measurements between the texts in vector space.
The distance between two vectors is calculated by leveraging their angle toward each other using the cosine. As the neural networks are trained to take into account linguistic phenomena such as ambiguity and synonymity in the vector representation, identical words with different meanings, or different words with the same meaning, carry less or more weight in the similarity measurement.
In the next step, the measured distances of each research paper from all the other research papers produce a square distance matrix, which serves as input data for hierarchical clustering. Research papers that display similarities to other research papers are identified here as being similar and are combined into a common cluster. Next, a special algorithm is used to extract every cluster’s key words, with which each cluster is ultimately labeled. The clustering results are displayed as a dendrogram.
The dendrogram can be labeled with various information, such as
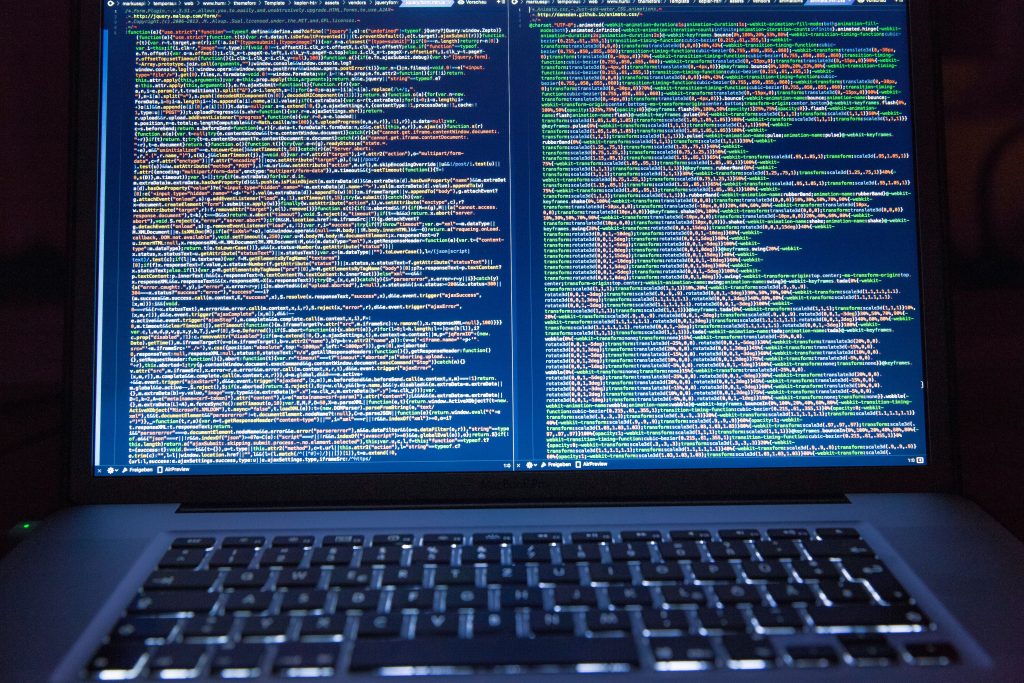
The following diagram shows the basic architecture of the analysis model on an abstract detail level.
Furthermore, a predetermined number of topics can be extracted from the corpus with the help of topic modeling methods. With topic modeling, each topic comprises a distribution of words that are important for the topic. Subsequently, a topic distribution can be calculated for each research paper on the basis of the words contained in it, which states the proportion of each paper that is devoted to a certain topic.
All this information helps experts to review the analyzed corpus faster and describe the clusters found systematically. As a result, the literature can be cast very efficiently into a structured reference manual, making the knowledge from research within an organization accessible effectively.
In industrial manufacturing, rapid advances in information and communication technology bring many new opportunities, such as
While the trend toward the systematic integration of cyber-physical systems is inevitable in manufacturing, highly technological knowledge is required to successfully incorporate sensor, database, and network technology into manufacturing processes.
This presents companies with the challenge of:
Manufacturing companies therefore have no choice: they must invest in research, so they can keep a constant eye on the latest opportunities and react promptly to new technologies and business trends.
To support research projects in the field of digital manufacturing, Otofacto collected a large number of research papers on the subject of “sensor data in industrial manufacturing” and evaluated and synthesized them by applying the analysis model. The research papers collected stem from some of the most renowned journals in the area of industrial manufacturing, for example, The Journal of Manufacturing Systems, The Journal of Intelligent Manufacturing, and The Journal of Manufacturing Science and Engineering.
The goal of the literature review was to gain an overview of the use cases and challenges of digital manufacturing with regard to sensor data applications and to provide the experts at Otofacto with straightforward and uncomplicated access to the solution concepts, architectures, and methods offered in research literature.
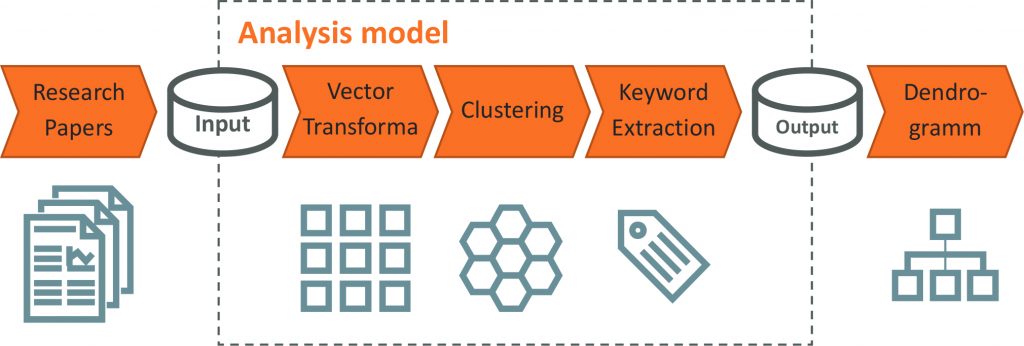
Even before a structure is given to the collection of literature using automated clustering, examining the most frequently occurring words already yields interesting information about the main topics, methods, and terms in the corpus.
In addition to single words, phrases comprising several words can be automatically identified with the help of artificial intelligence, and then counted.
These phrases oftentimes are especially informative. Figure 2 shows the most important words and phrases from our example of use.
It can immediately be seen, for example, that the notion of real time plays a very important role in this corpus, or that neural networks are discussed often. On the basis of the most frequent words and phrases, an initial catalog of terms can be created for the research project.
In addition, the topics from a topic model can already be examined and described in advance. Here, word clouds are suitable for the visualization, as Figure 3 shows for a few exemplary topics. The size of the words indicates their importance within each one of the topics.

For instance, the topics of “measurement of tool wear in milling with vibration signals” or “error detection in assembly with video data” can thus be found in the examples above. With the help of this visualization, experts can categorize these topics quickly and easily identify them as one concept that exists in the analyzed corpus in relation to the given terms.
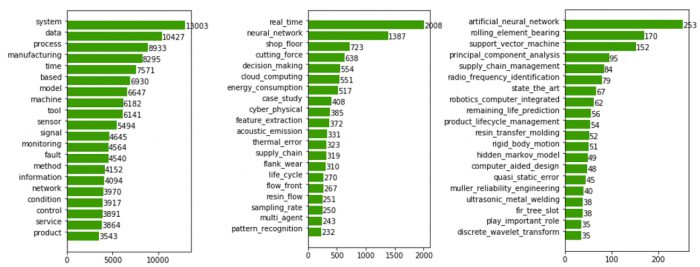
The first task of the analysis model for automated literature synthesis is to create hierarchical clusters of the research papers, after they have been transformed into high-dimensional vector representations. Figure 4 shows the dendrogram resulting from the clustering in our example and makes sub-dendrograms readable for selected clusters.
Vertical lines in the dendrogram show the distance threshold value at which two clusters are merged into one, while horizontal lines indicate the distance between two clusters. For forming the clusters, a distance threshold value is set (vertical dashed line), which can be determined heuristically or empirically.

The top cluster, for example, contains papers that deal with the modeling and compensation of thermal errors in machine tools, while the cluster below it is concerned exclusively with wireless sensor networks, and so on.
The dendrogram can also be labeled with the key words extracted from the titles of the chapters, as shown in Figure 5. Each line here corresponds with the most important key words for each of the clusters. For example, in the second line, we can see that the key words real time compensation, cnc machining center, thermal error, and error compensation were extracted – and these are very fitting for the top example in Figure 4. Overall, the key words provide meaningful descriptions.

As shown by this example, the analysis model is capable of forming coherent literature clusters, the likes of which humans could also have formed by investing considerable cognitive effort and time. The dendrogram can be read from the top to the bottom like the table of contents of a book. Like chapter titles, the extracted key words give an effective insight into the topics contained in those chapters.
Topical overlaps can easily be identified in adjacent clusters. In such a way, the chapter structure of a literature review can be very closely aligned with the cluster formation. Leveraging the hierarchical structure of the dendrogram, clusters can be divided into sub-chapters or merged into superordinate chapters. For further work using the research papers, the PDF versions can be stored in a folder structure based on the clusters found, to make them accessible in a structured way.
Figure 6 shows the main chapters formed for the literature review in Otofacto’s example, with reference to the clusters in the dendrogram.
Overall, the results of the analysis model greatly facilitate structuring and synthesizing hundreds or thousands of research papers. Exhaustive literature reviews can profit in particular, because a structured overview of the field being observed can be achieved easily and quickly. Crafting the literature review itself and extracting scientific insights – supported by the analysis results – are the creative tasks that remain for humans to perform.
Literature reviews are indispensable for research projects and they play an important role in accumulating knowledge within R&D companies.
The analysis model presented is capable of relieving knowledge workers of much of the cognitive effort that they would otherwise have to invest analyzing, structuring, and synthesizing the literature. It enables researchers to deal effectively with previously untamable volumes of literature and thus makes a big contribution to increasing their productivity in the review phase of research projects. The analysis model can therefore support and accelerate the structuring and organization of explicit knowledge in companies in the long term, and ultimately facilitate sustained competitive advantage.
By applying the analysis model in internal research projects, Otofacto has already convinced itself of the capabilities this analysis model provides and will continue to use it in research in order to offer the best expert knowledge for customers in all fields of business.
The model’s use cases, however, are not limited to the synthesis of literature in research projects. Wherever there are large quantities of unstructured text data to be analyzed and understood, the analysis model can be applied as a useful tool to increase efficiency and solve otherwise insurmountable tasks. The analyzed texts can comprise external data from the Internet – such as forum entries or tweets about a company’s products – which serve the interests of the marketing department.
Or, they may comprise internal data – such as maintenance reports for manufacturing machines – which can be analyzed to show engineers where there is potential to improve maintenance cycles and reduce machine downtimes.
What’s more, the development of search engines for a company’s internal text data is also conceivable, to produce the most relevant texts contained within the organization for given queries. Imagination and creativity alone are restricting the many ways in which text mining can be used in companies to solve business-relevant problems in the handling of unstructured data.
On request, Otofacto will help you assess the potential of applying text mining methods to your collections of unstructured text data, and will also help you develop and implement tailored text mining solutions.
Interested? Contact us!